Page 1 of 1
Unicode in scripting
Posted: 23 Aug 2009 05:09
by nf_xp

- 2009-8-23 10-36-19.gif (15.38 KiB) Viewed 1703 times
Don, I just tried Muroph's Tag Manager v2.2, and encountered the above error - After processed line #23, the first keyword 'input' of line #24 was broken into lines #23 and #24, as well as the 'replace' in line #25, 'substr' in line #26, etc.
After replaced ▲ and ▼ in line #23 (in raw script, they're in lines #190, #191, #211 and #212), this script runs well. So I guess Unicode is the cause of this bug.
Re: Unicode in scripting
Posted: 23 Aug 2009 16:01
by admin
nf_xp wrote:After replaced ▲ and ▼ in line #23 (in raw script, they're in lines #190, #191, #211 and #212), this script runs well. So I guess Unicode is the cause of this bug.
Yes, looks like. Currently no idea how to fix that because I don't even know exactly where/why the script was broken. It seems that the initial line parsing already chokes but why is "input" broken between "in" and "put"...

What happens if you put any other Unicode character there -- same error?
Re: Unicode in scripting
Posted: 23 Aug 2009 18:21
by nf_xp
Test 1:
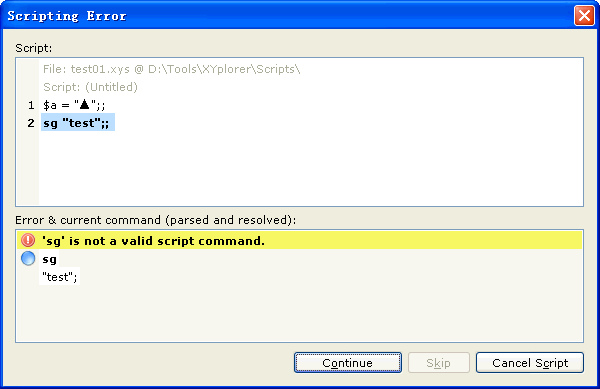
- 2009-8-23 23-36-47.gif (9.76 KiB) Viewed 1638 times
Test 2:
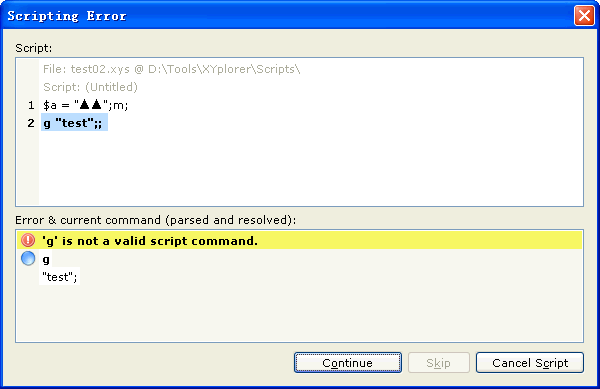
- 2009-8-23 23-37-06.gif (9.77 KiB) Viewed 1638 times
Raw view of the first test file in MBCS system:

- 2009-8-23 23-55-20.gif (4.42 KiB) Viewed 1640 times
My guess: You can see the MBCS string '$a = "▲";' takes 10 bytes in the raw view, but there are actually 9 Unicode chars after it's read into memory. Extra chars (from next line) will be read if using the byte number to break lines.
Re: Unicode in scripting
Posted: 23 Aug 2009 19:01
by admin
Thanks, really interesting! I forgot that there are Unicode that resolve to 2 chars when converted to ANSI.
Looks like I have to rewrite a couple of heavily used functions.
Re: Unicode in scripting
Posted: 24 Aug 2009 15:37
by nf_xp
Fixed
